介绍
MoneyPrinterPlus是一款使用AI大模型技术,一键批量生成各类短视频,自动批量混剪短视频,自动把视频发布到抖音,快手,小红书,视频号上的工具。
项目地址:https://github.com/ddean2009/MoneyPrinterPlus
环境依赖
ffmpeg: https://ffmpeg.org/
python环境
安装首先拉取项目到本地。
1git clone https://github.com/ddean2009/MoneyPrinterPlus
进入MoneyPrinterPlus目录,运行安装必须的依赖:
1pip install -r requirements.txt
然后运行:
1streamlit run gui.py
会自动开启浏览器,进入MoneyPrinterPlus界面。
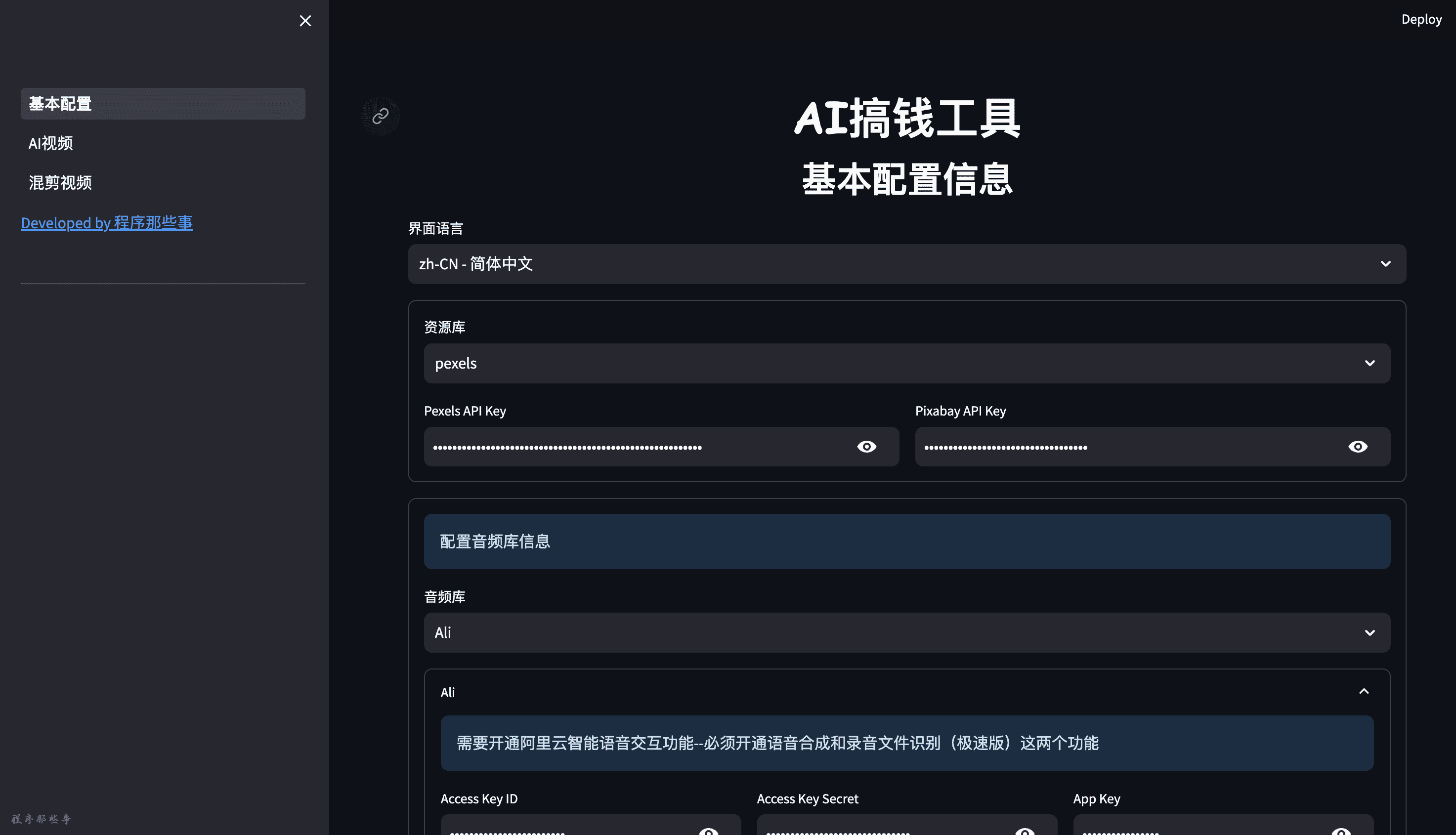
基本配置首先我们点击左边的基本配置,这里需要配置一些我们需要用到的资源信息。
资源库
资源库指的是我们从哪里获取视频或者图片信息,这里目前提供了两个资源提供方,分别是pexels和pixabay。
大家任意选择一个即可。
以pexels为 ...

Tailor 是令人惊叹的视频编辑神器!其人脸和语音剪辑精准无比,人脸识别能锁定人物画面,语音捕捉和裁剪独具魅力。视频生成方面,口播生成赋予图像灵魂,字幕生成准确契合,色彩生成让黑白鲜活,音频生成创造无限可能。优化上,背景更换如入奇幻世界,流畅度与清晰度也极佳。Tailor 不仅是软件,更是创意与精彩的钥匙,无论专业或普通爱好者都能借此让作品闪耀,快来体验它带来的震撼惊喜!
项目地址:https://github.com/FutureUniant/Tailor
介绍Tailor(中文简称:泰勒)是一款视频智能裁剪、视频生成和视频优化的工具。目前该项目包括了视频剪辑、视频生成和视频优化3大类视频处理方向,共10种方法。Tailor使用方法简单,点点鼠标即可使用最先进的人工智能进行视频处理工作,省时省力,若使用安装版本Tailor,所有的环境配置都可省掉,对用户特别友好。
Tailor界面主界面
工作界面
功能介绍Tailor包括了视频剪辑、视频生成和视频优化3大类视频处理方向,共10种方法。下面将依次进行介绍:
视频剪辑人脸剪辑Tailor 拥有神奇的人脸识别技术,能自动从视频中捕捉每一 ...
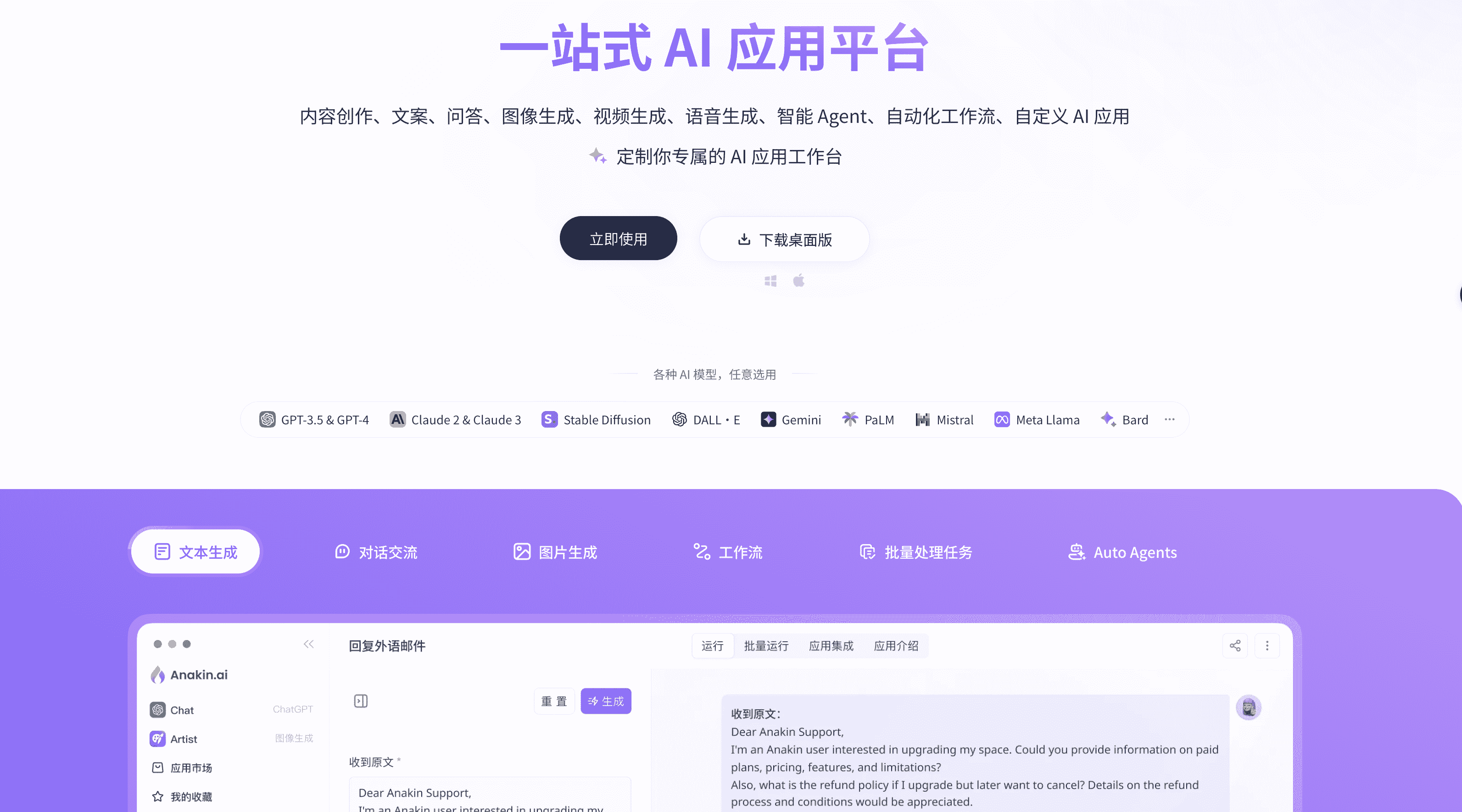
Anakin是一个集成了内容创作、文案、问答、图像生成、视频生成、语音生成、智能 Agent、自动化工作流、自定义 AI 应用的多功能AI 应用工作台
它是免费注册可使用的,免费版每日可获得30额度,另有基础班、专业版及高级版套餐
通过下方链接邀请注册你可获得200+官方100的额度奖励
300 额度地址:https://anakin.ai/?r=6IlA6CRu
邀请码6IlA6CRu
特征内置 1000+ AI 应用 满足各种场景需求
成千上万的 AI 应用可用于内容生成、问题回答、文档搜索和工作流程自动化等各种场景。可以选择任意一款应用直接使用,也可以根据自己的需要进行定制。
批支持量生成内容、清理数据、提取信息等。让我们来帮你处理速率限制和重复调试的工作,确保任务完成。
支持在几分钟内设计和部署属于你自己的文本生成应用程序。借助直观的可视化界面,你可以自定义从应用程序的外观到它生成的特定文本类型的所有内容。
支持智能&自动化各种复杂任务
支持外部API的调用
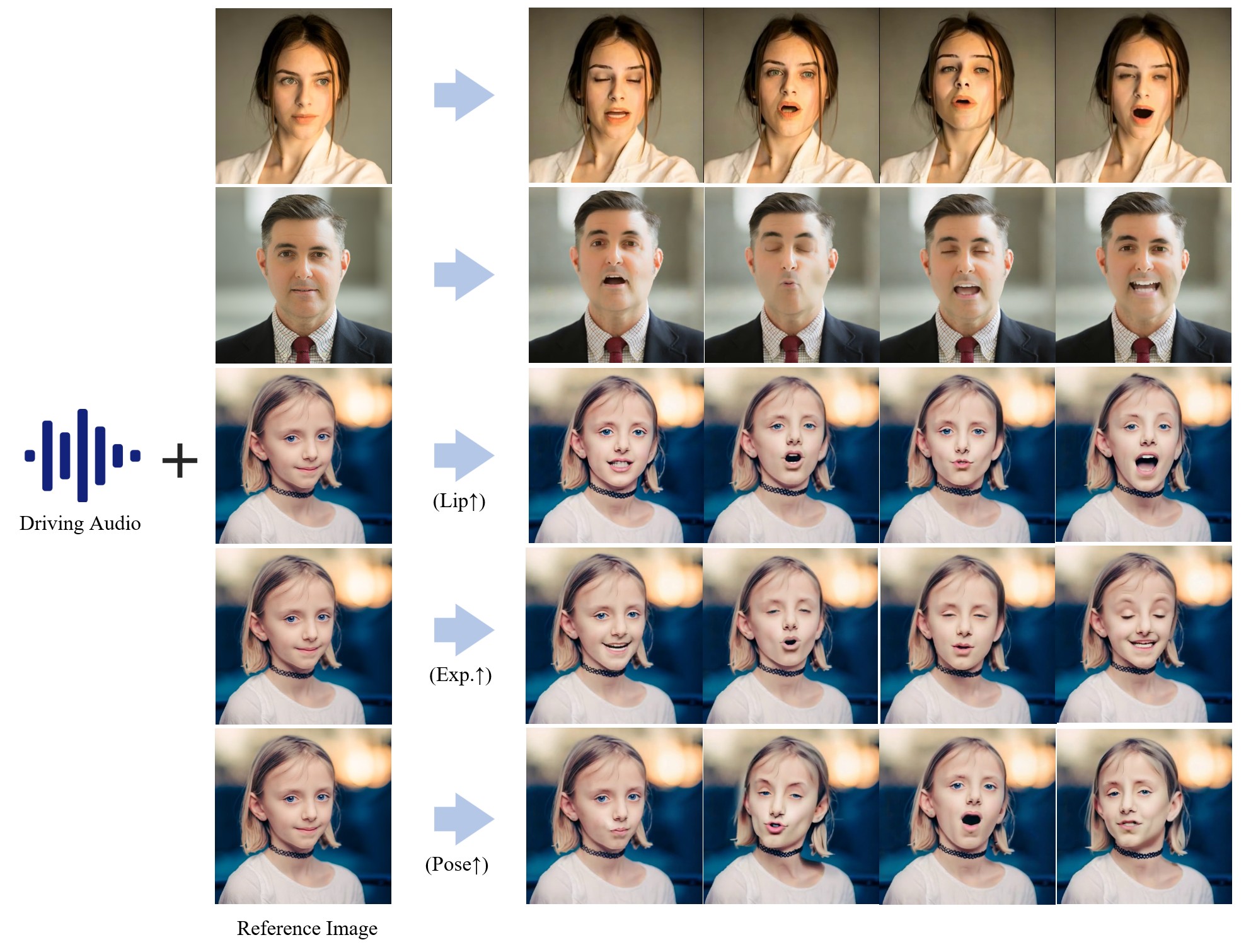
介绍hallo是一个用于人像图像动画的分层音频驱动视觉合成的项目,在使用语音音频输入的驱动下,人像图像动画领域在生成逼真和动态的人像。它采用了端到端扩散范式,并引入了分层音频驱动的视觉合成模块,以提高音频输入和视觉输出之间的对齐精度,包括嘴唇、表情和姿势运动。无缝集成了基于扩散的生成模型、基于UNet的降噪器、时间对齐技术和参考网络。所提出的分层音频驱动的视觉合成提供了对表情和姿势多样性的自适应控制,从而实现了针对不同身份的更有效的个性化。在图像和视频质量、唇形同步精度和运动多样性方面取得了明显的提高
此外,该项目支持与 ComfyUI 工具集成
官网:https://fudan-generative-vision.github.io/hallo/
github:https://github.com/fudan-generative-vision/hallo
启动整合包下载:https://pan.quark.cn/s/455b24f79fc6
演示
启动包说明启动整合包不包含训练模型,适用于WIN系统,大小6.8g,要求最低内存需要8G,训练模型可从 HuggingFace 存储库 ...

IDM-VTON(Improved Diffusion Models for Virtual Try-ON)是由韩国科学技术院和OMNIOUS.AI的研究人员提出的一种先进的AI虚拟试穿技术,通过改进扩散模型来生成逼真的人物穿戴图像,实现更真实的虚拟试穿效果。该技术包含两个关键组件:一是视觉编码器,用于提取服装图像的高级语义信息;二是GarmentNet,一个并行UNet网络,用于捕捉服装的低级细节特征。IDM-VTON还引入了详细的文本提示,以增强模型对服装特征的理解,从而提升生成图像的真实度。,同时支持Win和Mac,
下载:https://pan.quark.cn/s/9a3abbca0ad7
功能特色
虚拟试穿图像生成:根据用户和服装的图像,生成用户穿戴特定服装的虚拟图像。
服装细节保留:通过GarmentNet提取服装的低级特征,确保服装的图案、纹理等细节在生成的图像中得到准确反映。
支持文本提示理解:利用视觉编码器和文本提示,使模型能够理解服装的高级语义信息,如款式、类型等。
个性化定制:允许用户通过提供自己的图像和服装图像,定制化生成更符合个人特征的试穿效果。
逼真的 ...

介绍该SD启动器是由GetAI出品,具有一键安装下载启动的使用特性,你可以快速调用大模型及插件
下载:https://pan.quark.cn/s/38bcedb8162a

介绍这是一款集成 Dreambooth 和 LoRA 模型训练的Stable Diffusion WebUI 启动器,包含丰富的模型、插件,随时更新、内置丰富精选AI课程、内置丰富的AI工具导航站,轻松找到、海量AI工具
官网:https://www.easyartx.com/landing
下载:https://pan.quark.cn/s/e78b277bc1da
特征丰富的模型、插件随时更新支持丰富模型快速下载
支持丰富插件管理,即插即用
Dreambooth、LoRA模型训练针对新手、专家设置不同的模式,满足不同用户模型训练需求
一键快速安装,完全无忧
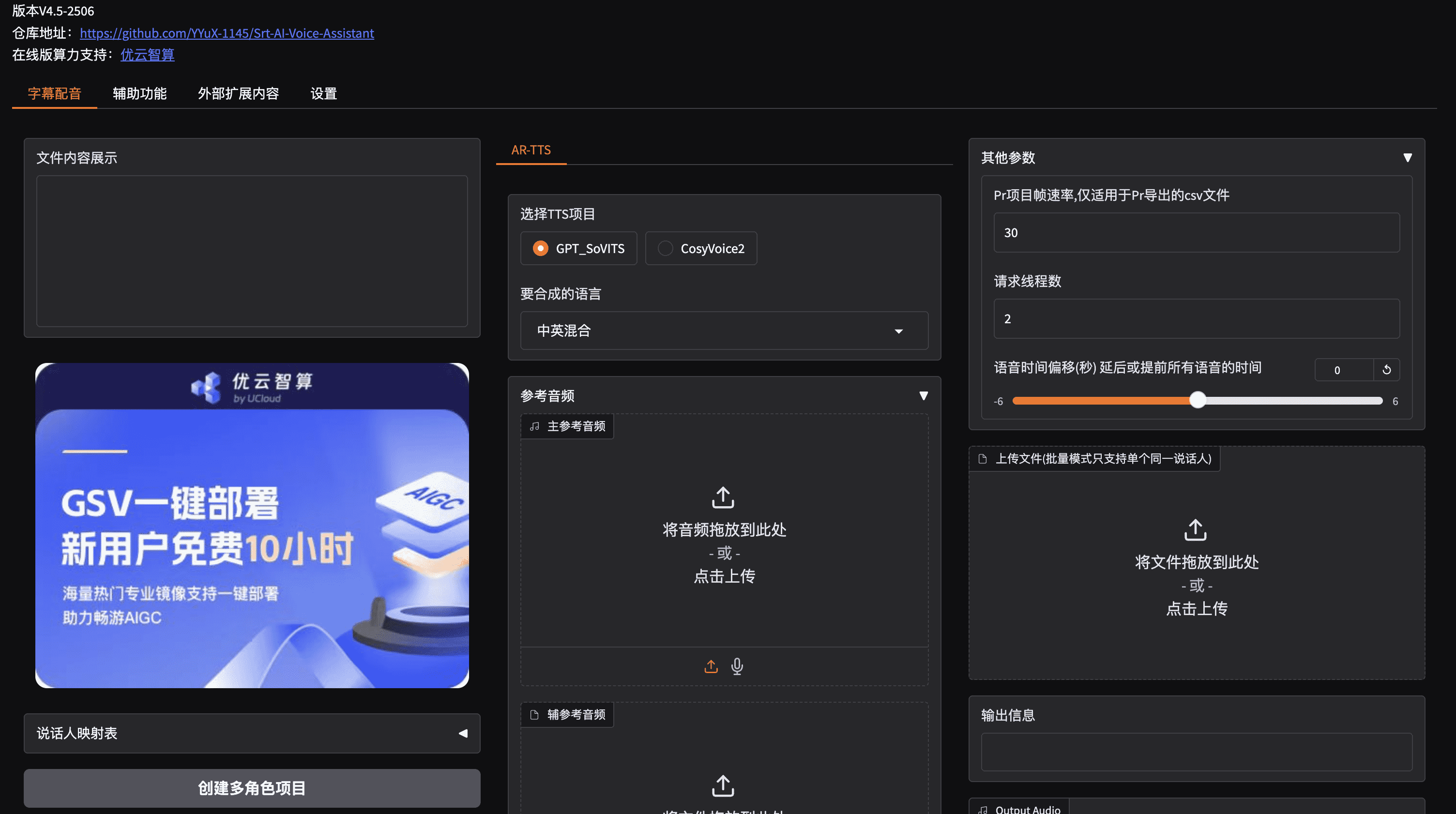
介绍
Srt-AI-Voice-Assistant是利用多个AI-TTS为你的字幕或文本文件配音。 并提供包括字幕识别、翻译在内的多种便捷的辅助功能。
项目地址:https://github.com/YYuX-1145/Srt-AI-Voice-Assistant
体验:srt-ai-voice-assistant-onlinedemo.work特性
✅ 代码开源,界面友好,本地运行,可局域网访问
✅ 支持多个TTS项目:BV2,GSV,CosyVoice2,AzureTTS,以及你可以自定义API!
✅ 保存个性化设置和预设
✅ 批量模式
✅ 字幕编辑
✅ 字幕批量翻译
✅ 单句重新抽卡
✅ 支持多角色配音
✅ 字幕重新导出
✅ 扩展功能:音视频字幕转录
✅ I18n
打包版:https://github.com/YYuX-1145/Srt-AI-Voice-Assistant/releases
网盘:https://pan.quark.cn/s/01e0362d9a23
当依赖冲突或无法正常安装时使用此版本
下载配合GPT-SoVITS的整合包(Hugging Face)
...



