简介Machete是砍刀,它能砍、能削、能切、能剁,最适合披荆斩棘;
砍刀不像大刀、长剑、长矛为战场而生,但在日常生活中使用也是得心应手。
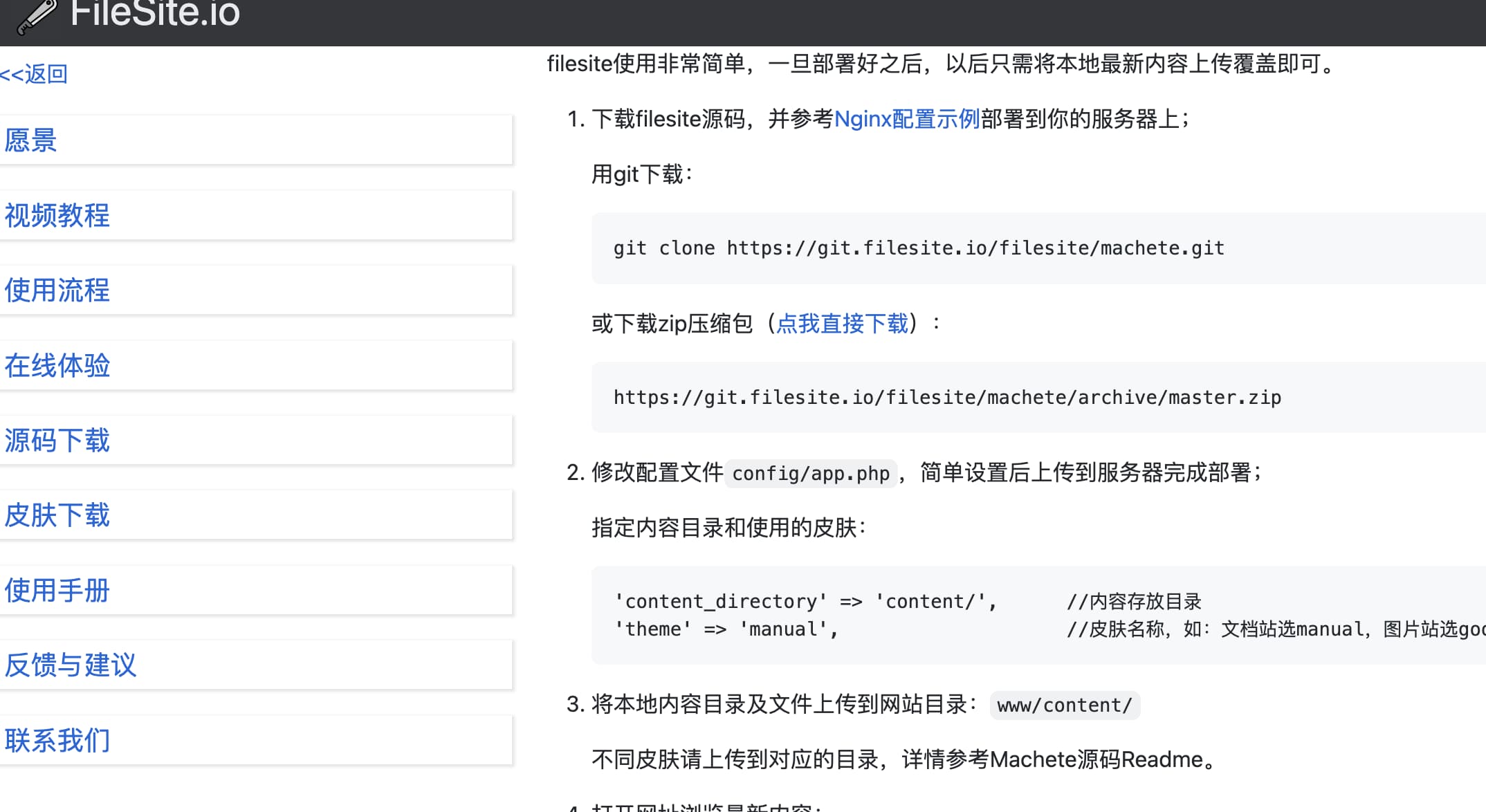
Filesite.io也一样,它短小精悍,使用它把常见的本地文件制作成网站,就像拿起砍刀一样简单
Github:https://github.com/filesite-io/machete
Docker使用从dockerhub下载镜像:
1docker pull filesite/machete
支持samba文件共享管理内容的版本:
1docker pull filesite/machete:samba
启动machete容器:
1docker run --name machete -p 1080:80 -itd filesite/machete [皮肤名]
samba文件共享版本容器启动:
1docker run --name machete_samba -p 1081:80 -p 445:445 -itd filesite/machete:samba [皮肤名]
其中皮肤名称可选值:
1234567[ &#x ...

由于单纯遭遇了恶意且微信腾讯没有通过申诉【奇葩,给我发了一个主域名,不带任何文章链接说违规链接,主域名怎么违规?】,所以我决定变更下域名,旧域名依然可用,请通过主页www.noisework.cn来打开本站!
当然,其它站也是存在类似的情况,不过问题不大,本身这个站点只是为了记录的博客站,今后还会一直存在
RVC是一个开源项目,代码已经在Github发布。
Retrilo based voice conversion,简称RVC,是基于WITS语音合成系统的变声器。可以实现完美实时变声,适合直播、视频录制等多种场景。这篇文章主要为大家介绍一下RVC的使用方法,以及在文章底部提供简单的一键安装包,方便大家本地部署和使用,其中有为大家提供最新的版本可以兼容各种版本的模型,稳定性也得到了提升。
可在Hugging Face下载各种版本。
配置要求处理器:13代Intel酷睿I7处理器
显卡:英伟达系列显卡(RTX 4070TI以上)
声卡:独立声卡
内存:64GB
麦克风:高质量麦克风
RVC配置要求比较苛刻,要求电脑性能较高,因为是需要实时把声音处理并且输出,非常消耗电脑性能。多线程CPU可以最大程度减少延迟,高质量的麦克风和声卡可以降低电流和噪声,效果也会更加的出色。
安装教程下载最新版本0528版本RVC安装包和模型包到本地,并解压文件。
Ps:文件名称需要设置为英文,否则无法正常运行。
其中有三个模型包,分别为:paidaxing、nzb、jiu,它们用来配置RVC使用的。
...

前言首先,感谢Daniel带来的项目docker-wechatbot-webhook,借助该项目,为后面的自动化集成工作流添加了无数可能
介绍这个项目https://github.com/danni-cool/docker-wechatbot-webhook是将个人微信作为 webhook 机器人,支持docker部署,登录为电脑、iPad方式
部署拉取镜像1docker pull dannicool/docker-wechatbot-webhook
启动容器(后台常驻)1234 docker run -d \--name wcRoomBot \-p 3001:3001 \dannicool/docker-wechatbot-webhook
登录1docker logs -f wcRoomBot
这里我主要介绍当微信可以用作webhook时,如何加入到自己的自动化工作流中,以n8n平台为示例,案例为将每日新闻简报自动发布到微信群组。
案例1-每日新闻一、以慧语简报https://news.topurl.cn 为例,打开https://news.topurl.cn/api 查看它 ...

介绍轻木用于组织想法、跟踪项目以及与您的团队协作
一个非常适合制作软件的文档 - 能够在一个地方编写规范并将计划付诸行动。
简化的文本格式,使文档易于编写和阅读愉快
结构化模块,如里程碑,可以为时间表和名单等视图提供支持
从文档到执行的一体化工作流程,没有过时文档或切换工具的开销
一个非常适合制作软件的文档 - 能够在一个地方编写规范并将计划付诸行动。
简化的文本格式,使文档易于编写和阅读愉快
结构化模块,如里程碑,可以为时间表和名单等视图提供支持
从文档到执行的一体化工作流程,没有过时文档或切换工具的开销
读取和写入美丽
我们的文档编辑器是产品、技术和设计规范的完美工具 - 既实用又令人愉悦。
适用于
产品经理,需要编写规范和计划并将其传达给团队
工程师,需要了解项目的要求和依赖关系
需要与工程师和其他利益相关者协作的设计师
高管,他们需要随时了解项目进度并根据数据做出明智的决策
官网访问:https://www.balsa.com/
AI 建议 • 刷新
问题陈述
特征直观的大纲模式
文本格式化(所见即所得)和模块突出
里程碑和任务段
图像注释:能够注释屏幕截图/ ...
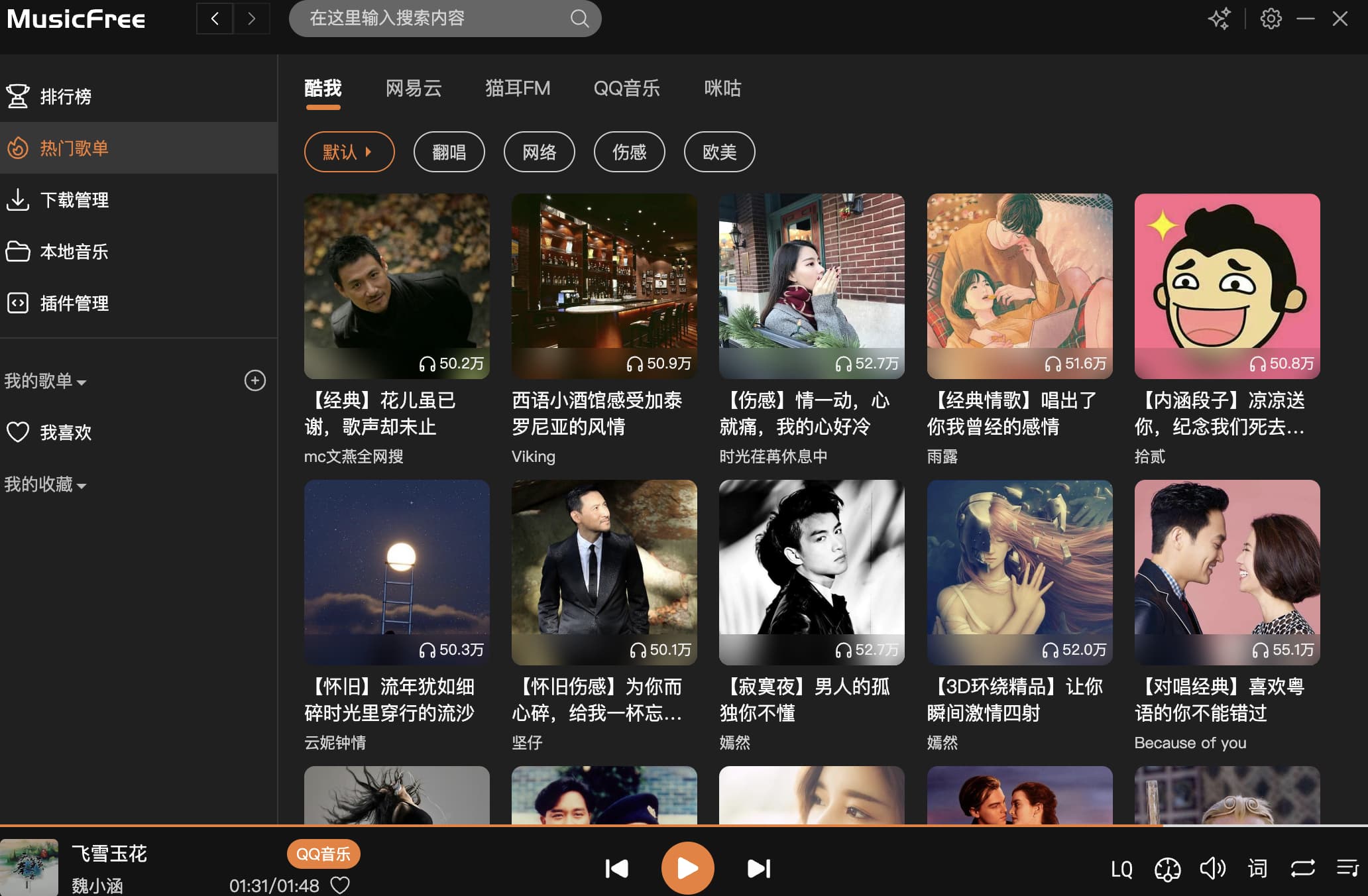
介绍软件是一个跨平台支持安卓、pc、mac的音乐播放软件,软件默认是一个本地音乐播放器,可以通过【插件】扩展第三方源
[下载地址]蓝奏云下载地址
GitHub:https://github.com/maotoumao/MusicFreeDesktop
[特性]
插件化:本软件仅仅是一个播放器,本身并不集成任何平台的任何音源,所有的搜索、播放、歌单导入等功能全部基于插件。这也就意味着,只要可以在互联网上搜索到的音源,只要有对应的插件,你都可以使用本软件进行搜索、播放等功能。 关于插件的详细说明请参考 安卓版 Readme 的插件部分。
插件支持的功能:搜索(音乐、专辑、作者、歌单)、播放、查看专辑、查看作者详细信息、导入单曲、导入歌单、获取歌词等。
定制化:本软件可以通过主题包定义软件外观及背景,详见下方主题包一节。
无广告:基于 GPL3.0 协议开源,将会保持免费。
隐私:软件所有数据存储在本地,本软件不会上传你的个人信息。
[插件]插件协议和安卓版完全相同。
示例插件仓库,你可以根据插件开发文档 开发适配于任意音源的插件。
音乐源安装(插件中选择从网络安装):https:// ...
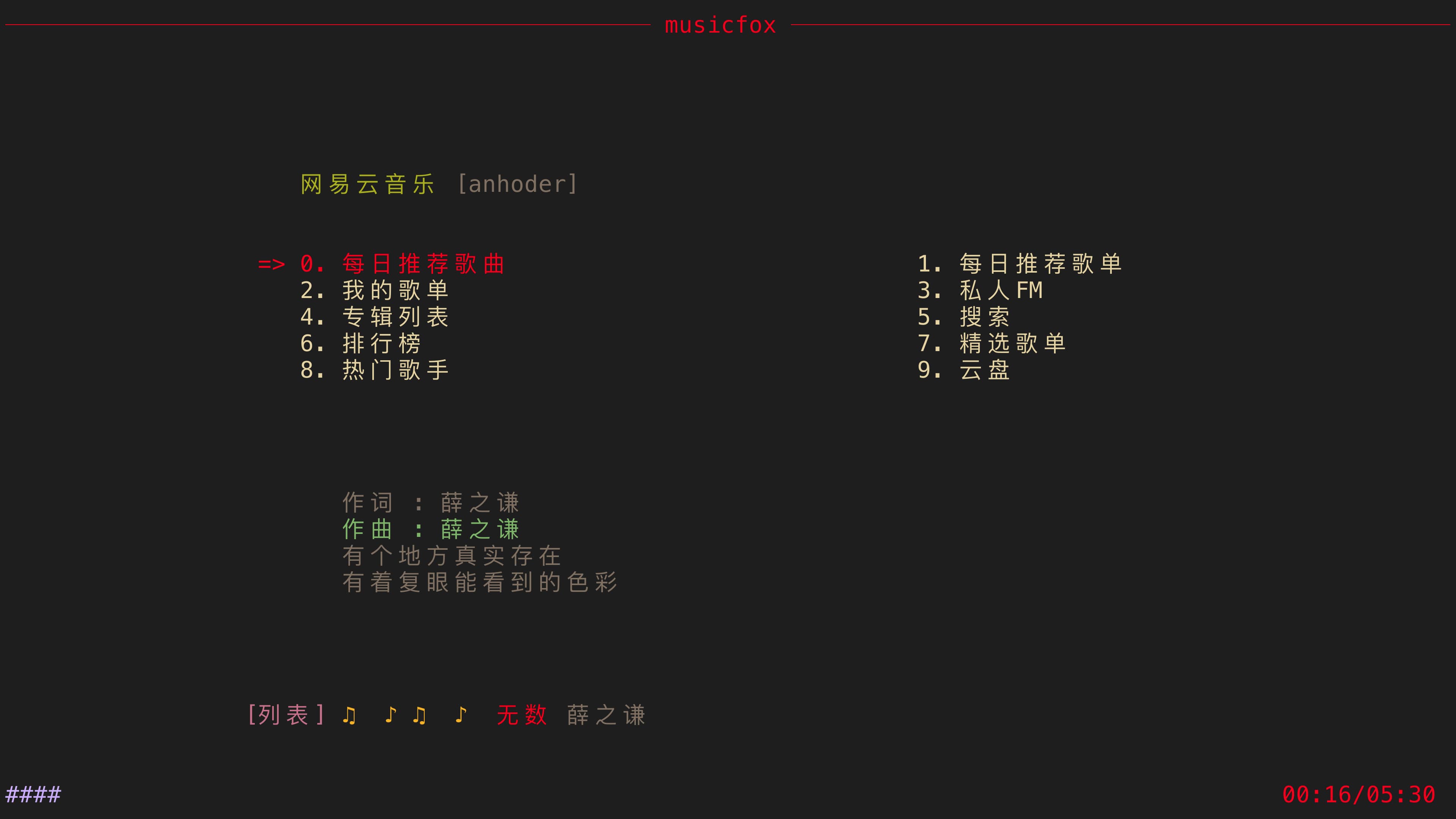
介绍go-musicfox是用Go写的又一款网易云音乐命令行客户端,支持UnblockNeteaseMusic、各种音质级别、lastfm、MPRIS、MacOS交互响应(睡眠暂停、蓝牙耳机连接断开响应、菜单栏控制等).
1. 启动
2. 主界面
3. 通知
4. 登录
5. 搜索
6. Last.fm 授权
7. macOS NowPlaying
8. UnblockNeteaseMusic
9. macOS 歌词显示
需要满足以下条件:
go-musicfox >= v3.7.7
下载和安装 LyricsX 的 go-musicfox 的 fork 版本
在 LyricsX 设置中,打开使用系统正在播放的应用
安装[macOS][1. 通过 Homebrew 安装]1$ brew install anhoder/go-musicfox/go-musicfox
如果你之前安装过 musicfox,需要使用下列命令重新链接:
1$ brew unlink musicfox && brew link --overwrite go-musicfox
...
特征支持带文本的链接及视频ID
代码放入PHP环境中即可
示例https://noisevip.cn/douyin/
源码:123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168<?php$finalUrl = "";$errorMs ...



