开源视频翻译和配音工具
开源视频翻译和配音工具
noise介绍
这是一个离线运行的本地语音识别转文字工具,基于 fast-whipser 开源模型,可将视频/音频中的人类声音识别并转为文字,可输出json格式、srt字幕带时间戳格式、纯文字格式。可用于自行部署后替代 openai 的语音识别接口或百度语音识别等,准确率基本等同openai官方api接口
Github:https://github.com/jianchang512/stt
官方文档:https://v.wonyes.org
特征
语音自动生成字幕
生成字幕后,可在软件中对字幕进行修改后再生成配音
多种配音角色可选择
可选edgeTTS多种配音角色,并支持openai的TTS模型配音
支持多种翻译引擎
google+chatGPT+DeepL+Baidu+DeepLX+Gemini+tencent
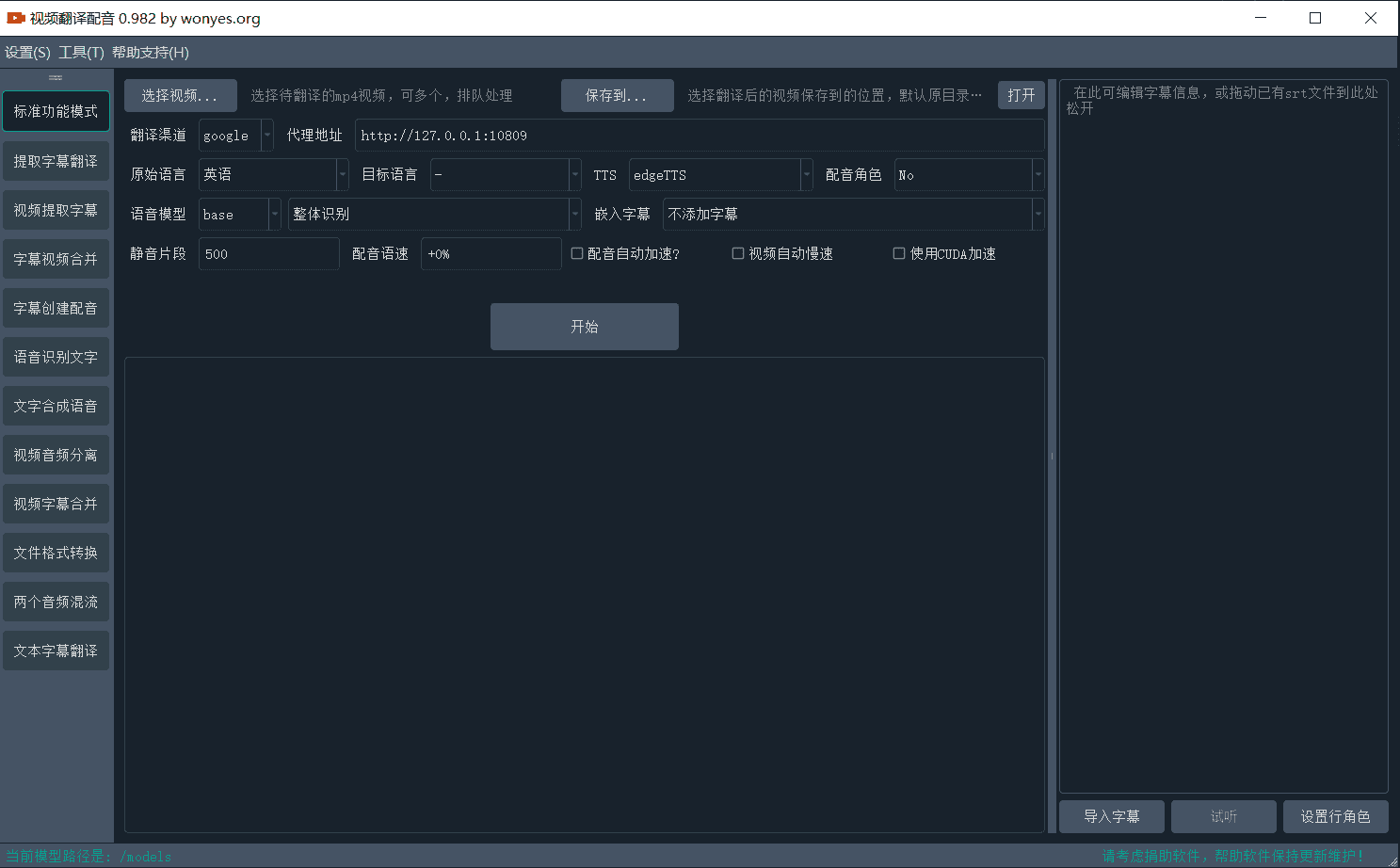
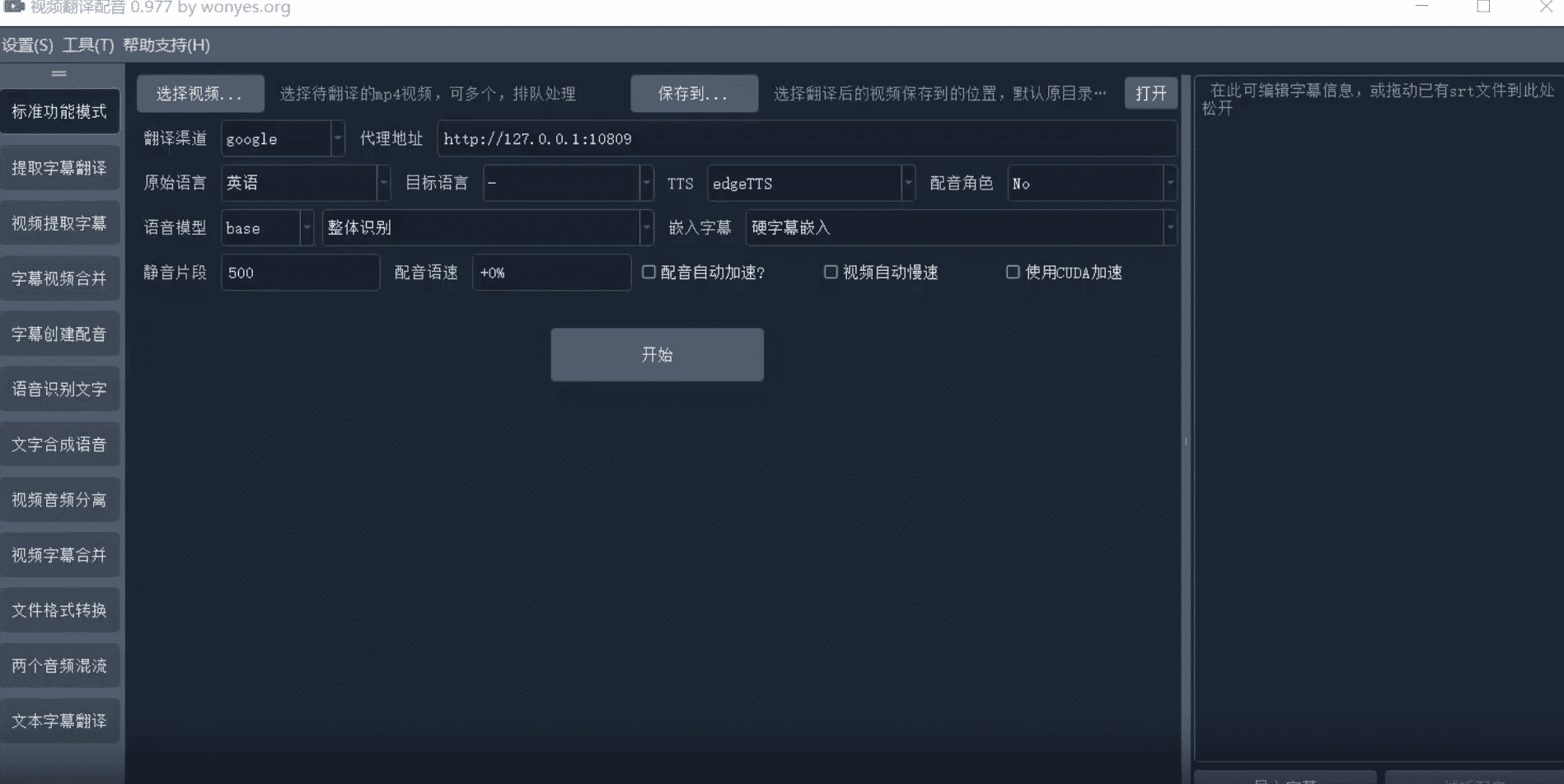
主要用途和使用方式
【翻译视频并配音】根据需要设置各个选项,自由配置组合,实现翻译和配音、自动加减速、合并等
【提取字幕不翻译】选择视频文件,选择视频源语言,则从视频识别出文字并自动导出字幕文件到目标文件夹
【提取字幕并翻译】选择视频文件,选择视频源语言,设置想翻译到的目标语言,则从视频识别出文字并翻译为目标语言,然后导出双语字幕文件到目标文件夹
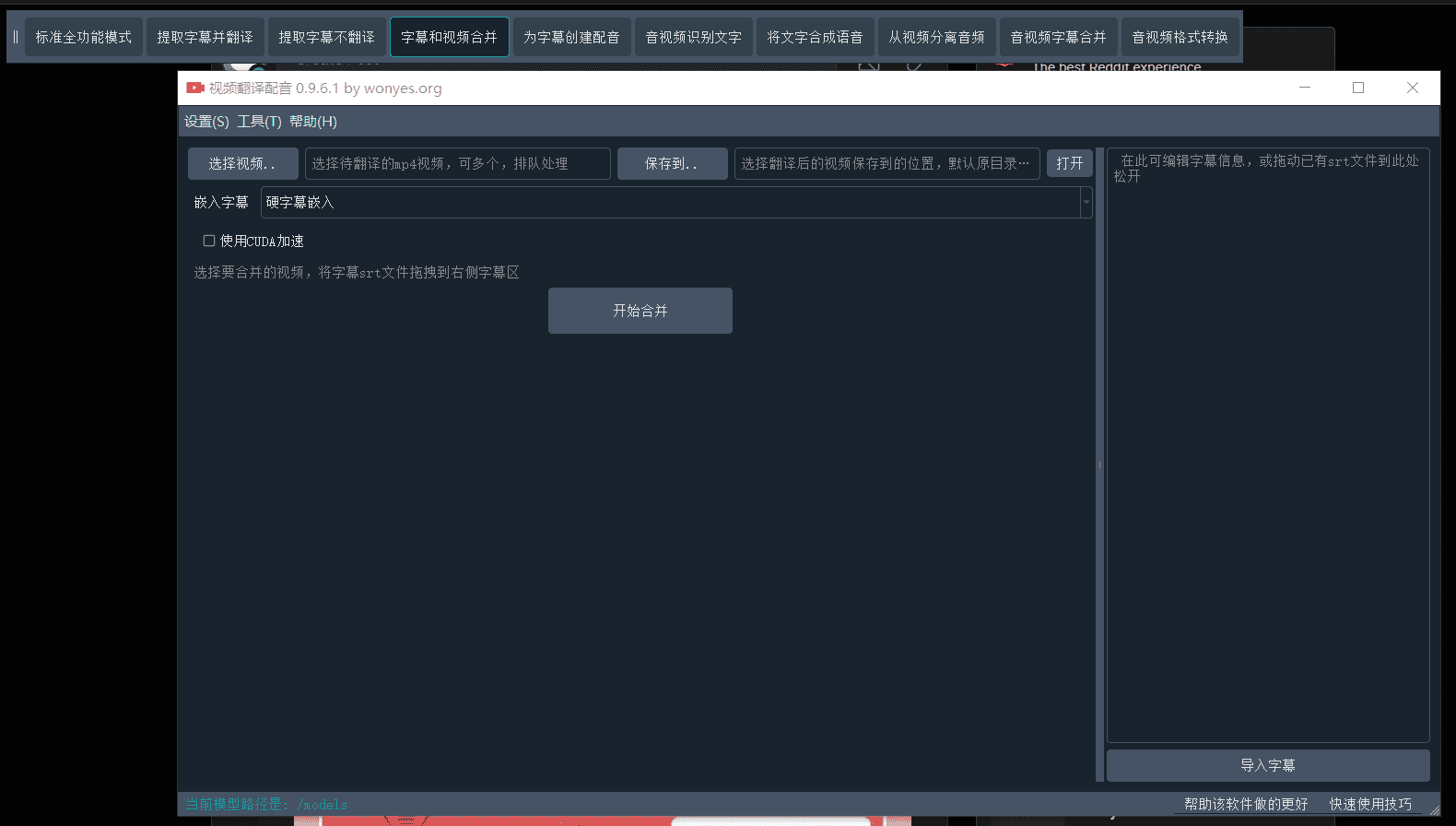
【字幕和视频合并】选择视频,然后将已有的字幕文件拖拽到右侧字幕区,将源语言和目标语言都设为字幕所用语言、然后选择配音类型和角色,开始执行
【为字幕创建配音】将本地的字幕文件拖拽到右侧字幕编辑器,然后选择目标语言、配音类型和角色,将生成配音后的音频文件到目标文件夹
【音视频识别文字】将视频或音频拖拽到识别窗口,将识别出文字并导出为srt字幕格式
【将文字合成语音】将一段文字或者字幕,使用指定的配音角色生成配音
【从视频分离音频】将视频文件分离为音频文件和无声视频
【音视频字幕合并】音频文件、视频文件、字幕文件合并为一个视频文件
【音视频格式转换】各种格式之间的相互转换 【文字字幕翻译】将文字或srt字幕文件翻译为其他语言
全部模型下载地址:https://github.com/jianchang512/stt/releases/tag/0.0
源码部署
- 配置好 python 3.9->3.11 环境
git clone https://github.com/jianchang512/pyvideotranscd pyvideotranspython -m venv venv- win下执行
%cd%/venv/scripts/activate,linux和mac执行source ./venv/bin/activate pip install -r requirements.txt,如果遇到版本冲突报错,请使用pip install -r requirements.txt --no-deps- win下解压 ffmpeg.zip 到根目录下 (ffmpeg.exe文件),linux和mac 到 ffmpeg官网下载对应版本ffmpeg,解压到根目录下,注意必须是直接将可执行文件 ffmpeg 放在根目录下
python sp.py打开软件界面- 如果需要支持CUDA加速,需要设备具有 NVIDIA 显卡,具体安装防范见下方 CUDA加速支持
预览