前言 这是一个自媒体常用案例,今天我们通过分析这个案例来获得有关python的学习和使用
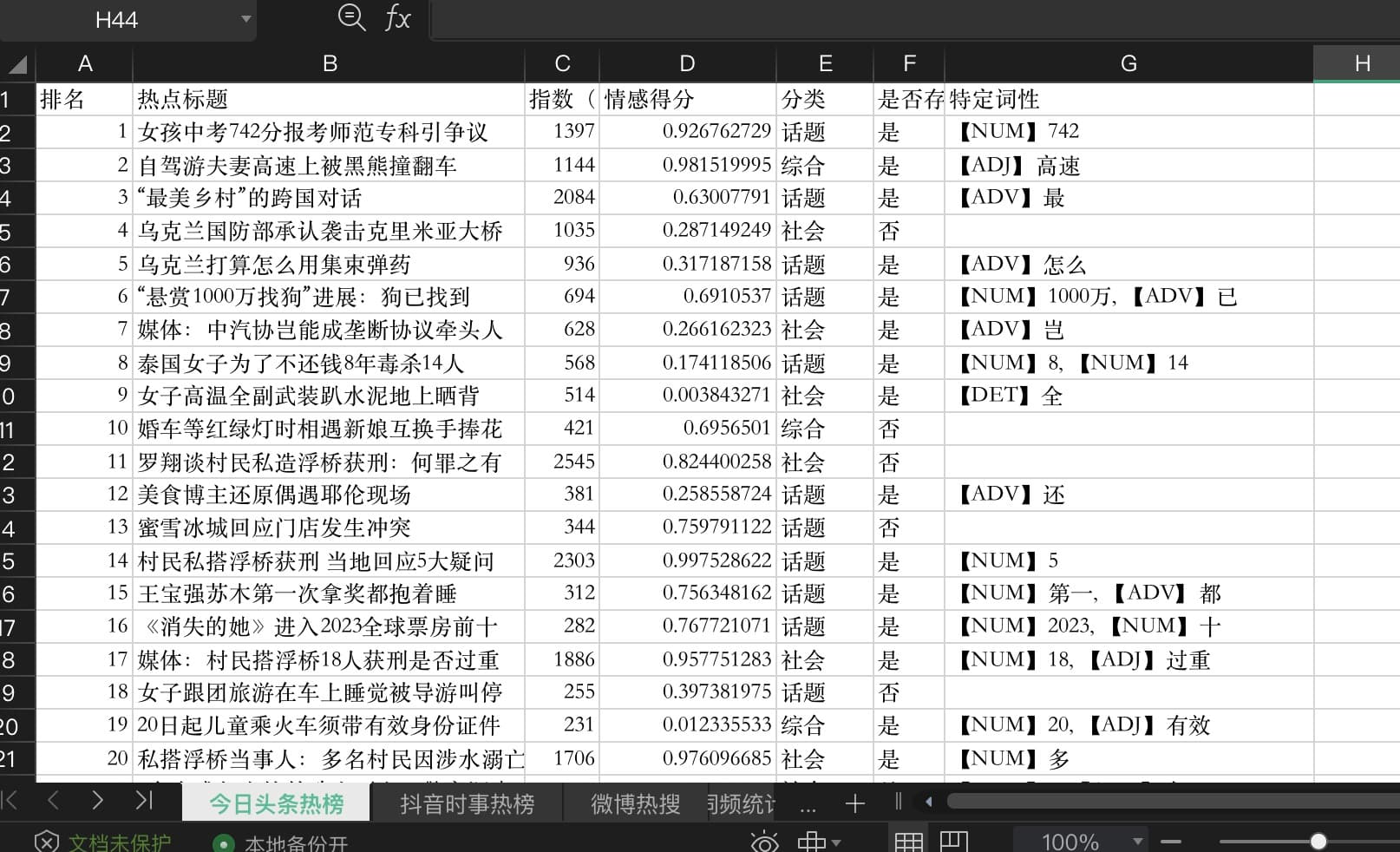
效果 通过运行py脚本输出本地得到xlsx数据表格文件
自动化分类;整体匹配率:84%~96% 区间左右。
词频统计;三者共存的热搜,说明为持久公共热度,信息密度较高。
文本情感平均值、每条标题的情感数值;主:人为置顶热搜的文本情绪强烈程度。
词性分析;标记可能存有引导与被植入意识成分用词,只要定语、状语叠得多,总能是宣传正态形势。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 import osfrom datetime import datetimeimport requestsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookfrom snownlp import SnowNLPimport jiebafrom collections import Counterimport jieba.posseg as psegimport jsonimport urllib.requestdef get_formatted_time (): """ 获取格式化后的当前时间 :return: 格式化后的当前时间字符串 """ now = datetime.now() return now.strftime('%Y-%m-%d' ) def get_news_from_url (url: str ): """ 从指定的 URL 抓取热搜新闻 :param url: 网页 URL :return: 热搜新闻列表 """ headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } r = requests.get(url, headers=headers) r.encoding = 'utf-8' soup = BeautifulSoup(r.text, 'html.parser' ) toutiao_resoubang = soup.find_all('div' , class_='single-entry tindent' ) resoubang_list = [] for item in toutiao_resoubang: spans = item.find_all('span' ) for span in spans: resoubang_list.append(span.string) return resoubang_list def delete_empty_rows (sheet_name: str , wb: Workbook ): """ 删除指定工作表中的空行 :param sheet_name: 工作表名称 :param wb: Excel 工作簿对象 :param None 关键字 https://notes-by-yangjinjie.readthedocs.io/zh_CN/latest/python/05-modules/openpyxl.html?highlight=openpyxl """ ws = wb[sheet_name] for row in ws.iter_rows(): if all (cell.value is None for cell in row): ws.delete_rows(row[0 ].row) def calculate_average_index_and_sentiment_score (sheet_name: str , wb: Workbook ): """ 计算指定工作表中热搜新闻的平均指数和情感得分 :param sheet_name: 工作表名称 :param wb: Excel 工作簿对象 :return: 平均指数、情感得分元组 """ ws = wb[sheet_name] total_index = 0 count = 0 sentiment_score_list = [] for row in ws.iter_rows(min_row=2 , min_col=1 , max_col=3 ): news_str = '' for cell in row: if cell.value is not None : news_str += str (cell.value) s = SnowNLP(news_str) sentiment_score = s.sentiments sentiment_score_list.append(sentiment_score) total_index += row[2 ].value count += 1 ws.cell(row=row[0 ].row, column=4 , value=sentiment_score) return (total_index / count, sum (sentiment_score_list) / len (sentiment_score_list)) def calculate_word_count (sheet_names: list , wb: Workbook ): """ 计算工作表中出现最多的20个单词,将结果写入新的工作表中 :param sheet_names: 工作表名称 :param wb: Excel 工作簿对象 :param stopwords_file: 停用词文件路径 停用词是指在自然语言中使用频率很高, 但通常不具有实际含义或对文本分析任务没有太大帮助的单词,如“的”,“了”等。 """ stopwords_file = 'https://ghproxy.com/https://raw.githubusercontent.com/goto456/stopwords/master/cn_stopwords.txt' response = requests.get(stopwords_file) stopwords = response.content.decode('utf-8' ).split('\n' ) for word in stopwords: jieba.del_word(word.strip()) word_count = Counter() for sheet_name in sheet_names: ws = wb[sheet_name] for row in ws.iter_rows(min_row=2 , min_col=1 , max_col=3 ): news_str = '' for cell in row: if cell.value is not None : news_str += str (cell.value) words = jieba.lcut(news_str) new_words = [] for word in words: if len (word) <= 1 : continue if not (word.isdigit() or (word.replace('w' , '' ).replace('.' , '' ).isdigit())): new_words.append(word) words = new_words word_count.update(words) for word in list (word_count): if word in stopwords: del word_count[word] top_words = word_count.most_common(30 ) ws = wb.create_sheet(title='词频统计' ) ws.append(['排名' , '词语' , '词频' ]) for i, (word, freq) in enumerate (top_words,1 ): ws.append([i, word, freq]) def write_category_to_sheet (sheet_name: str , wb: Workbook ): """ 将新闻事件的关键词分类信息写入到 Excel 工作表中的第五列中 :param sheet_name: 工作表名称 :param wb: Excel 工作簿对象 :jieba分词:https://github.com/fxsjy/jieba """ response = urllib.request.urlopen('https://ghproxy.com/https://raw.githubusercontent.com/hoochanlon/scripts/main/AQUICK/category_news.json' ) json_data = response.read().decode('utf-8' ) category_keywords = json.loads(json_data) ws = wb[sheet_name] for row in ws.iter_rows(min_row=2 , min_col=1 , max_col=4 ): title_str = '' for cell in row: if cell.value is not None : title_str += str (cell.value) words = pseg.cut(title_str) category = '' for word, flag in words: for key, keywords in category_keywords.items(): if word in keywords: category = key break if category: break if not category: category = '综合' ws.cell(row=row[0 ].row, column=5 , value=category) def write_news_to_sheet (news_list: list , sheet_name: str , wb: Workbook ): """ 将新闻列表写入到 Excel 工作表中 :param news_list: 新闻列表 :param sheet_name: 工作表名称 :param wb: Excel 工作簿对象 :cell.value.isnumeric() 表示当前字符串是否能表示为一个数字 :isinstance(cell.value, str) 表示当前值是否字符串 """ ws = wb.create_sheet(title=sheet_name) row = [] for i, item in enumerate (news_list, start=1 ): if i >= 156 : continue if i % 3 == 1 : item = item.replace("、" , "" ) row.append(item) if i % 3 == 0 : ws.append(row) row = [] for row in ws.iter_rows(min_row=2 , min_col=1 ): for cell in row: if cell.column == 1 or cell.column == 3 : if isinstance (cell.value, str ) and not cell.value.isnumeric(): cell.value = cell.value.replace('[置顶]' , '185w' ) if isinstance (cell.value, str ) and cell.value.isnumeric(): cell.value = int (cell.value) elif isinstance (cell.value, str ): cell.value = float (cell.value.replace('w' , '' )) ws.cell(row=1 , column=3 , value='指数(万)' ) ws.cell(row=1 , column=4 , value='情感得分' ) ws.cell(row=1 , column=5 , value='分类' ) def main (): urls = ['http://resou.today/art/11.html' , 'http://resou.today/art/22.html' ,'http://resou.today/art/6.html' ] sheet_names = ['今日头条热榜' , '抖音时事热榜' , '微博热搜' ] wb = Workbook() wb.remove(wb['Sheet' ]) for url, sheet_name in zip (urls, sheet_names): news_list = get_news_from_url(url) write_news_to_sheet(news_list, sheet_name, wb) delete_empty_rows(sheet_name, wb) write_category_to_sheet(sheet_name, wb) average_index, sentiment_score = calculate_average_index_and_sentiment_score(sheet_name, wb) print (f'{sheet_name} 平均指数:{average_index:.2 f} 情感得分: {sentiment_score:.2 f} ' ) calculate_word_count(sheet_names, wb) save_path_xlsx_file = os.path.join(os.path.join(os.path.expanduser("~" ), "Desktop" ), "resoubang_{}.xlsx" .format (get_formatted_time())) wb.save(save_path_xlsx_file) if __name__ == '__main__' : main()
分析 透过代码我们首先看到代码第一部分导入了一些常用的Python库和模块
import os:这是Python的标准库之一,用于与操作系统进行交互,例如创建文件夹、删除文件等操作。
from datetime import datetime:从datetime模块中导入datetime方法,用于处理日期和时间的功能。
import requests:这是一个非常常用的库,用于发送HTTP请求,例如获取网页内容。
from bs4 import BeautifulSoup:从BeautifulSoup模块中导入BeautifulSoup类,用于解析和提取HTML或XML文档中的数据。
from openpyxl import Workbook:从openpyxl模块中导入Workbook类,用于操作Excel文件。
from snownlp import SnowNLP:从snownlp模块中导入SnowNLP类,用于中文文本情感分析。
import jieba:这是一个非常常用的中文分词库,用于将中文文本分割成一个个单词。
from collections import Counter:从collections模块中导入Counter类,用于对一个可迭代对象进行计数。
import jieba.posseg:导入jieba库中的posseg模块,用于中文词性标注。
import json:这是Python的标准库之一,用于处理JSON数据。
import urllib.request:这是Python的标准库之一,用于发送HTTP请求和处理URL。
整体部分解释 它使用了上面多个第三方库来实现不同的功能。
接下来,代码定义了一个函数get_formatted_time(),用于获取格式化后的当前时间。
然后,代码定义了一个函数get_news_from_url(url: str),用于从指定的URL抓取热搜新闻。
接着,代码定义了一个函数delete_empty_rows(sheet_name: str, wb: Workbook),用于删除指定工作表中的空行。
然后,代码定义了一个函数calculate_average_index_and_sentiment_score(sheet_name: str, wb: Workbook),用于计算指定工作表中热搜新闻的平均指数和情感得分。
接下来,代码定义了一个函数calculate_word_count(sheet_names: list, wb: Workbook),用于统计工作表中出现最多的20个单词。
然后,代码定义了一个函数write_category_to_sheet(sheet_name: str, wb: Workbook),用于将新闻事件的关键词分类信息写入到Excel工作表中。
接着,代码定义了一个函数write_news_to_sheet(news_list: list, sheet_name: str, wb: Workbook),用于将新闻列表写入到Excel工作表中。
最后,代码定义了一个函数main(),用于执行主要的程序逻辑。它首先定义了要抓取的URL和工作表名称的列表,然后创建了一个Excel工作簿对象。接着,它使用get_news_from_url()函数抓取热搜新闻,并使用write_news_to_sheet()函数将新闻列表写入到Excel工作表中。然后,它使用delete_empty_rows()函数删除空行,并使用write_category_to_sheet()函数将关键词分类信息写入到Excel工作表中。接着,它使用calculate_average_index_and_sentiment_score()函数计算平均指数和情感得分,并打印结果。最后,它使用calculate_word_count()函数统计词频,并将工作簿保存为xlsx文件。
最后,代码使用if __name__ == '__main__':条件语句判断当前模块是否被直接执行,如果是,则调用main()函数执行主程序逻辑。
使用 安装python
下载Python:首先,您需要下载并安装Python解释器。您可以在Python官方网站(https://www.python.org)上找到不同版本的Python。选择适合您操作系统的版本并下载安装程序。
安装Python:运行下载的安装程序,并按照安装向导的指示进行安装。确保选择将Python添加到系统路径中的选项。
如果要运行Python文件:打开命令提示符(Windows)或终端(Mac/Linux),导航到存储了Python脚本的目录。使用cd命令来切换目录,例如:cd C:\Users\YourUsername\Documents然后,可以运行以下命令来执行Python脚本:python example.py这样,您就可以安装和运行Python文件了。如果一切顺利,您应该能够在命令提示符或终端中看到输出结果。
注:python3.x版本运行python3 example.py才会执行文件
设置python的全局环境变量
打开终端应用程序。您可以在“应用程序”文件夹中找到它,或者使用Spotlight搜索并输入“终端”。
在终端中,输入以下命令来编辑您的bash配置文件(如果您使用的是Zsh,请将命令中的.bash_profile替换为.zshrc):
终端将打开一个文本编辑器,显示您的bash配置文件的内容(如果您没有创建过配置文件,则会是空白的)。
在文件的末尾添加以下行来设置Python的全局环境变量:
1 export PATH="/usr/local/bin:$PATH"
这将将/usr/local/bin目录添加到您的PATH环境变量中,该目录通常是Python安装的位置。
按下Control + X来退出文本编辑器,然后按下Y来保存更改,最后按下Enter键确认保存的文件名。
在终端中,输入以下命令来使更改生效:
这将重新加载您的bash配置文件,使更改立即生效。
现在,您已经成功设置了Python的全局环境变量。您可以在终端中运行python命令来验证是否正确设置。
正确验证服务器证书 如果在使用python时urllib库发送HTTPS请求出现了证书验证失败的问题
为了解决这个问题,您可以尝试以下步骤:
打开终端应用程序。
输入以下命令并按Enter键:
1 /applications/python\ {your_python_version}/install\ Certificates.command
请将{your_python_version}替换为您当前使用的Python版本号。例如,如果您使用的是Python 3.10,则命令应为:
1 /applications/python\ 3.10/install\ Certificates.command
执行上述命令后,将会自动下载并安装缺失的根证书。
这个命令会运行Python安装目录中的Install Certificates.command脚本,用于安装缺失的根证书。执行此命令后,您的Python环境应该能够正确验证服务器证书,而不会再出现证书验证失败的错误。
PIP安装文件依赖库
输入以下命令来检查是否已经安装了pip:
如果已经安装了pip,您将看到pip的版本信息。如果未安装,您将看到一条错误消息。
如果未安装pip,您可以使用以下方法之一来安装它:
对于Windows用户:
对于Mac和Linux用户:
在命令行中运行以下命令来安装pip:
1 2 curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py sudo python get-pip.py
安装完成后,您可以再次运行以下命令来验证pip是否已成功安装:
如果显示了pip的版本信息,那么pip已经成功安装了。
现在可以在终端使用以下命令安装所需的依赖库:pip install requests beautifulsoup4 openpyxl snownlp jieba要使用import os和from datetime import datetime这两个库,它们是Python的内置库,无需安装。至于import jieba.posseg as pseg和import urllib.request,它们是Python标准库的一部分,也不需要单独安装。如果使用pip安装时出现权限问题,可以添加–user参数来将库安装在用户目录下:pip install –user requests beautifulsoup4 openpyxl snownlp jieba
最后,在满足python必要环境、文件所需依赖库的情况下使用终端命令或python解释器直接运行文件即可。