CosyVoice-AI声音克隆离线整合包

CosyVoice-AI声音克隆离线整合包
noise
介绍
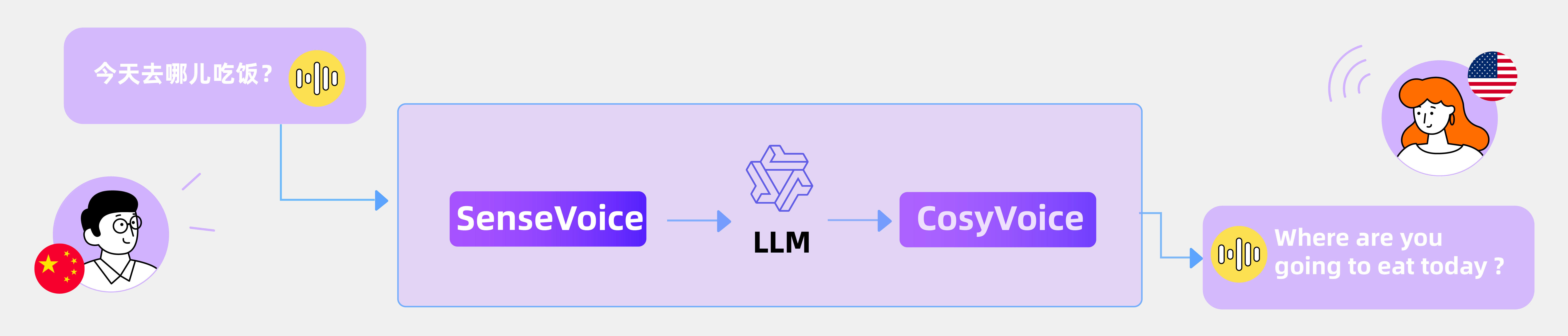
该项目是由阿里开源的聚合多语言大语音生成模型,提供推理、训练和部署全栈能力,项目中FunAudioLLM为核心框架,其两个主要模型用于高精度多语言语音识别、情感识别和音频事件检测的 SenseVoice;以及 CosyVoice,用于通过多语言、音色和情感控制进行自然语音生成。SenseVoice 提供极低的延迟并支持 50 多种语言,而 CosyVoice 在多语言语音生成、零样本语音生成、跨语言语音克隆和指令跟踪功能方面表现出色。与 SenseVoice 和 CosyVoice 相关的模型已在 Modelscope 和 Huggingface 上开源,以及 GitHub 上发布的相应训练、推理和微调代码。通过将这些模型与 LLM 集成,FunAudioLLM 实现了语音翻译、情感语音聊天、交互式播客和富有表现力的有声读物旁白等应用,从而突破了语音交互技术的界限
项目地址:https://github.com/FunAudioLLM/CosyVoice
CosyVoice整合包下载:https://pan.quark.cn/s/74ce36f251b6
引:整合包由up主十个骑士制作

这里分享的为CosyVoice相关,所以不过多介绍其框架下的综合能力,详细你可以访问官方https://fun-audio-llm.github.io 页面查看
解压整合包并启动后(其中有三个个一键启动程序,推理-instruct.exe为自然语言控制模型启动)你可以得到如下界面:

预训练模式即文本生成语音,在列表中你可以找到预训练的模型角色

3s极速复刻为克隆一段音频音色,上传音频文件并输出prompt(和音频内容一致)再填入你想要生成音频的文本(最上方)

跨语种复刻为克隆为其它语言的音频,所以上方输入的文本应为其它语言

自然语言控制需要推理-instruct.exe文件来启动对应模型
比较容易理解的是它可通过提示词来控制声音生成的情感等

其它不过多介绍,但该项目将AI语音带到了一个新的高度是毋庸置疑的,希望感兴趣的小伙伴可以多关注官方的开源页面更新进度